Once Upon a Token: Tales of GPTs
Mirror, mirror on the wall,
What's the magic behind it all?
The bots that chat, the tools that write,
Spinning words from dawn till night.
Hey there, Aditya here! First off, thanks for stopping by and reading this—yes, you, the one who probably just got distracted from scrolling through cat memes or arguing with strangers on the internet. I see you. And hey, props to you for taking a break from all that chaos to hang out with me (and my words).
Now, buckle up, buttercup, because by the end of this little joyride, you'll either learn something new or walk away thinking about old stuff in a way that makes you go, "Huh, I never thought of it like THAT before!" Either way, congrats—you're officially smarter than you were ten minutes ago. Or at least funnier. Probably both. Let's dive in, shall we?
The idea of computers talking like humans isn't new. In fact, it's been around since the 1950s — back when computers were the size of fridges and had the processing power of a potato. People back then already dreamed of machines that could chat like your overly enthusiastic friend who just discovered something new. Fast forward more than half a century, and here we are — chatting with computers that can write Shakespearean sonnets, debug your code, explain quantum physics and help you write Tinder bios. But make no mistake — what looks like AI magic today is actually the result of decades of mind-melting research in computer science, and enough scary mathematics to haunt you in your dreams.

Well, I don't know if you guys are old enough to remember this, but trust me—he was the OG user of LLMs!
So before we jump into how these digital word wizards actually work, let's take a moment to appreciate the glorious chaos that led us here — a beautiful mess of algorithms, neurons (the fake kind), and late-night research breakthroughs probably powered by caffeine and existential dread.
History of Large Language Models

Here's a visual representation of how large language models have evolved over time
1. N-Gram Models
-
Before neural networks, language modeling was more like a high-stakes guessing game. N-gram models estimated the probability of a word based on the last n-1 words. For example, a bigram model (n=2) would guess the next word using only the current word.
-
Under the hood, it maintained a large frequency table built from a massive text corpus. For example, for the input "I am going to the," it looks for common phrases and picks the most likely next word, like "store."
-
But it started to hit its limits as the window size increased, resulting in a lack of deeper understanding.
2. Recurrent Neural Networks
-
To overcome n-grams' short-sightedness, Recurrent Neural Networks (RNNs) emerged.
-
It was designed to process sequences of data, where the output depends on previous inputs — like sentences!
-
It passes information through loops, so each word updates a hidden state that carries over to the next. This lets the model theoretically remember past context from the entire sentence.
-
But it suffers from vanishing gradients — meaning they "forget" older words as the sequence grows. They also struggle with parallel processing, making training slow.
3. Long Short-Term Memory Networks
-
It was a type of RNN that introduced special gates to control what to keep and what to forget. It became the go-to method for early chatbots, speech recognition, and translation tools.
-
These gates use numbers between 0 and 1 to control the flow of information.
-
It has three types of gates, forget gate, input gate and output gate.
-
The forget is responsible for deciding what to forget, the input gate is responsible for what to add and the output gate is responsible for what to show.
-
This made them much better at modeling longer contexts (like 50–100 words) and remembering important information.
4. Transformers
-
In 2017, Google researchers dropped a bombshell on the deep learning world with their paper: "Attention is All You Need." This introduced the Transformer architecture — the backbone of all modern LLMs.
-
It ditched recurrence (no loops!) and introduced a mechanism called self-attention.
-
This means the model can "look at" any other word in the sentence, no matter where it is, and weigh its importance.
-
The benefits were that it was way faster to train (since it processes all words in parallel), can model long-range dependencies easily and scales very well with more data and compute.
5. Bi-directional Encoder Representations from Transformers
-
It took the Transformer idea and applied it to understanding language.
-
It reads sentences in both directions (left-to-right and right-to-left) at the same time.
-
It's trained using Masked Language Modeling (randomly hide words and ask BERT to fill them in) and Next Sentence Prediction.
-
It's excellent at understanding meaning, context, and relationships — ideal for tasks like classification, Q&A, and sentence similarity. But it isn't great at generating text.
-
It's like an expert reader, not a storyteller.
6. Generative Pre-Trained Transformers
-
Then came OpenAI's GPT (Generative Pre-trained Transformer), which focused on generating human-like text.
-
It was trained on massive text corpora (general datasets like the internet) to predict the next word in a sentence, one token at a time.
-
It uses causal transformers (which only attend to previous tokens, not future ones).
-
GPT was the first model that truly felt like you were talking to a thinking machine — complete with curiosity, creativity, and sometimes, unprompted dad jokes.
Now, that we understand about how we got here, let's explore about GPT in a little bit more detail.
Generative Pre-Trained Transformers
Generative Pre-trained Transformers (GPT) are easily one of the most revolutionary technologies of the 21st century. They're the product of countless hours of intense research, heavy-duty math, and brain-melting computer science concepts.
But don't worry — understanding GPT isn't as terrifying as it sounds.
To most people, it feels like straight-up wizardry: a machine that takes your input and magically replies with sentences that make sense — sometimes eerily so. But there's no magic wand here, just clever engineering (and a lot of GPUs).
In this section, we'll break down what GPT actually is — starting with a plain, no-jargon explanation. Then we'll peek under the hood just enough to appreciate the tech behind it (don't worry, no heavy math — we're trying to sleep peacefully tonight, remember?).
Decoding GPTs
Astonishingly, GPT is just an acronym made up of three simple words: Generative, Pre-trained, and Transformer. Let's break down what each of these terms really means, and then piece them together to understand the magic behind GPT!
Generative:
Let's go with first principles.
What comes to your mind when you hear the word generative?
You might say, "Adi, it gives the intuition of something being generated."
To that, I'd say — you're a megamind.
That's exactly what it means! Any GPT model can generate text — it's not just reading or analyzing; it's actively producing new sentences.
If GPT were a person, it would be the one who's great at storytelling, writing poems, composing emails, or even going on rants about pineapple on pizza.
Pre-Trained:
In the context of GPT, pre-trained means the model has already been trained on a massive amount of data from nearly every indexable corner of the internet.
This phase teaches the model how language works — grammar, common facts, logic, slang, memes, and all that jazz.
If GPT were a student, "pre-trained" means it has already spent years reading everything it could get its hands on. So when it shows up to your chat, it's not clueless — it's already loaded with knowledge.
Transformer:
Now, this one's a bit more complex — we'll dive deeper into the architecture later. But sticking to first principles, what does a transformer sound like?
Something that transforms, right?
Just like a juicer takes raw oranges and transforms them into orange juice — a transformer takes raw input text and transforms it into meaningful output text.
In fact, the original Transformer architecture was introduced by Google and was used in things like Google Translate.
Sounds easy, right? Don't worry — we'll complicate it later when we get into the juicy (pun intended) technical details of how transformers really work.
Architecture of Transformers
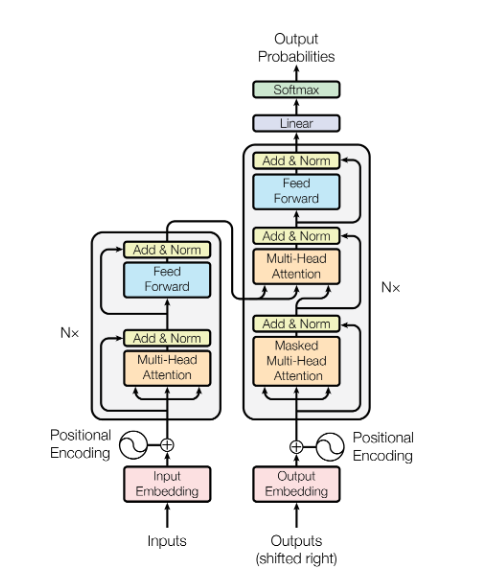
Let's try to digest this using layman analogy.
Imagine the encoder (one on the left side) is a super attentive reader that reads a sentence and makes super detailed notes. The decoder (one on the right side) is a genius writer who uses those notes to write a reply — one word at a time, checking every time with the reader to see if the reply makes sense.
Step by Step Working of GPTs
Now, let's move on to a step-by-step high-level working of a GPT
Step-0 (Giving the Input)
You give something input to GPT to process. You can throw anything at GPT—an essay with more grammatical errors than trees in the Amazon rainforest, code that breaks more than it builds, or even a confession about the mysterious AWS button you pressed that wiped the production database. GPT's seen it all—and it's still here to help, no judgment.
Step-1 (Tokenization)
GPT doesn't understand plain language the way humans do. In fact, it doesn't understand "language" at all — it understands numbers. Predictions aren't made in English, Hindi, or Spanish — they're made in the universal language of mathematics. That's why any input we give it, whether it's an essay, a joke, or a line of code, has to be converted into numbers first. But this isn't a direct jump — there's a process.
The first step is called tokenization, which means breaking down the input text into smaller pieces called tokens. Each GPT model has its own specific way of doing this. These tokens are then mapped to unique numbers using a predefined vocabulary.
If you want to see this in action, check out https://tiktokenizer.vercel.app. Type in any sentence, and you'll see how the text is split into tokens and converted into their corresponding token IDs — the building blocks that GPT can understand.
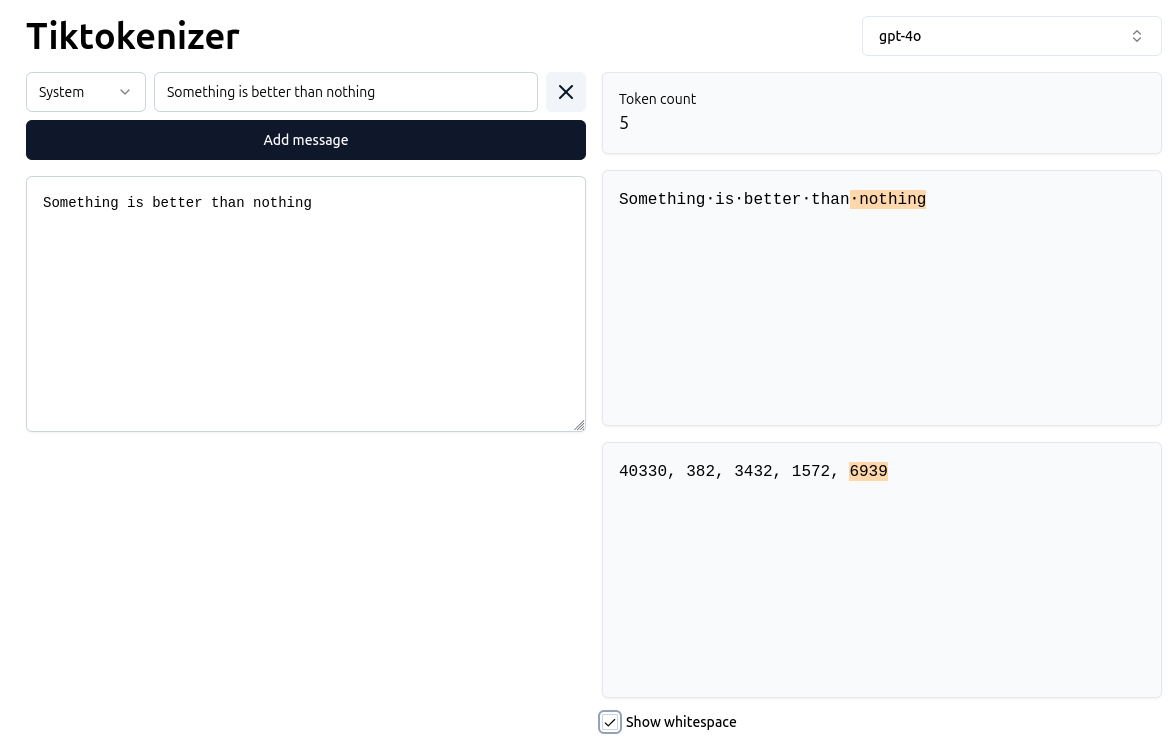
This is an example of tokenizing some text based on gpt-4o
Let's take another example by using a library called tiktoken by openAI
import tiktoken # Selecting the encoding model enc = tiktoken.encoding_for_model("gpt-4o") # Dummy text text = "Something is better than nothing" # Creating encoded sequence of the dummy text encoded_tokens = enc.encode(text=text) print("Encoded Tokens:", encoded_tokens) # Creating decoded sequence of the encoded text decoded_tokens = enc.decode(encoded_tokens) print("Decoded Tokens:", decoded_tokens)
If you run the following program you'll get

Which is basically the encoded tokens and the decoded tokens.
Step-2 (Vector Embeddings)
But even after converting words into numbers, machines still don't truly "understand" them. Why? Because those numbers by themselves don't carry any context or meaning — at least not in a way a computer can use effectively. Remember, computers speak only in the language of mathematics, so we need to represent meaning in mathematical terms too.
That's where vector embeddings come in. They help us translate raw tokens into rich, meaningful representations by capturing relationships and context in a form that machines can process. Essentially, embeddings give structure to language in mathematical space — allowing models like GPT to reason, relate, and generate text that feels intelligent.
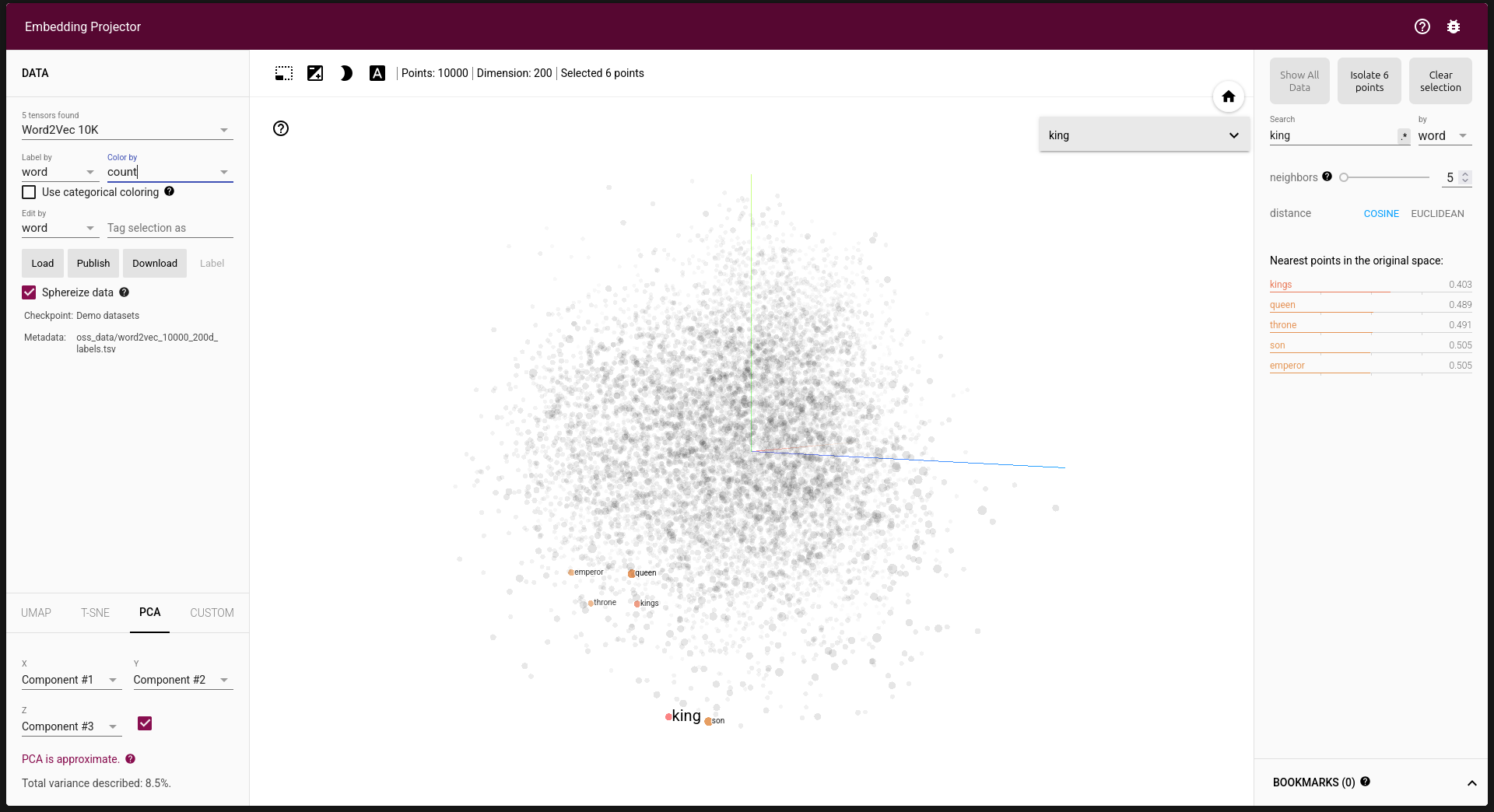
An image from https://projector.tensorflow.org/ showing how vector embeddings appear in a 3D vector space. (P.S.: If you learned about vector mathematics in school or college, this is exactly that!)
Let's try some practical via using the google embedding model named models/embedding-001
import os import google.generativeai as genai from dotenv import load_dotenv load_dotenv() try: api_key = os.getenv("GEMINI_API_KEY") except KeyError: print("Please set the GEMINI_API_KEY environment variable.") exit() genai.configure(api_key=api_key) result = genai.embed_content( model="models/embedding-001", content="Something is better than nothing") print(result['embedding'])
When we run this code, we can see the returned vector embedding from the model
Image of vector embeddings for the given text
Let me also give you another visual example
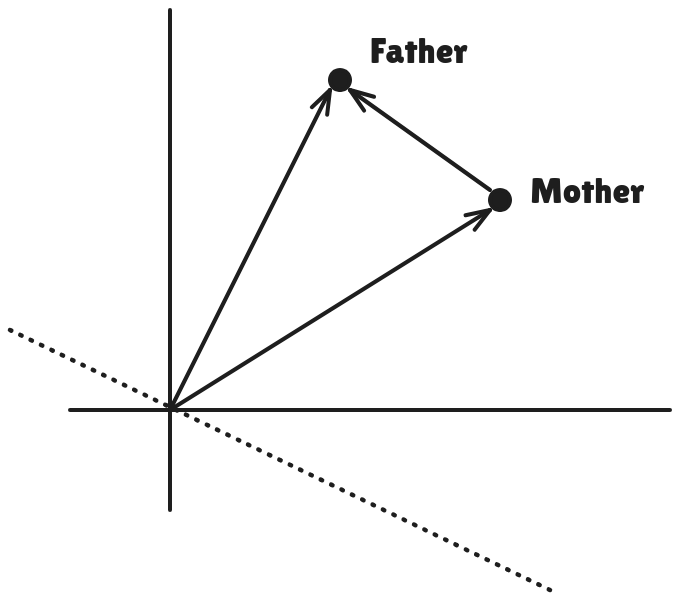
Let's say we have the above example, in which we have some vectors pointing to word, "Mother" and "Father".
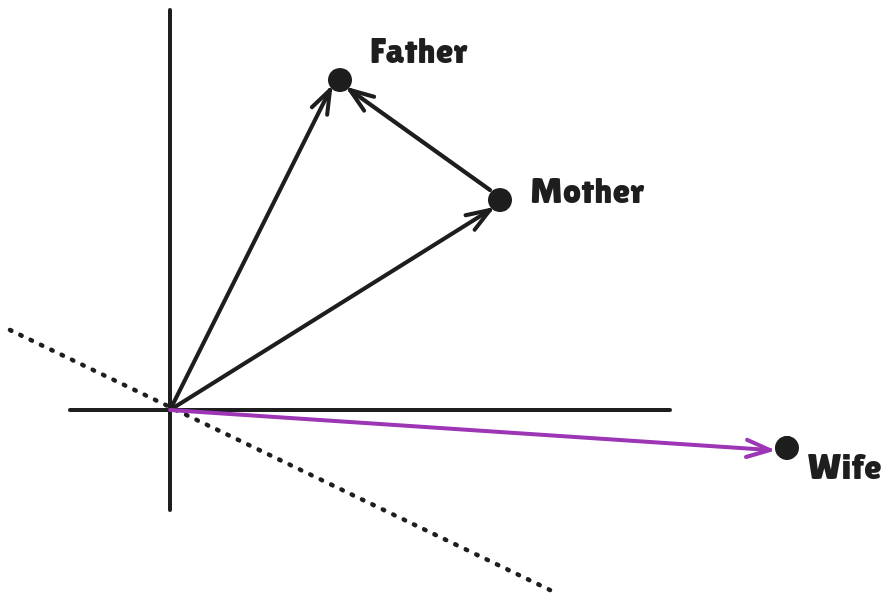
Now, let's say we have a new word "Wife", so what we can achieve via having these relations is, we'll be able to find "Husband" just using the context of "Mother" and "Father".
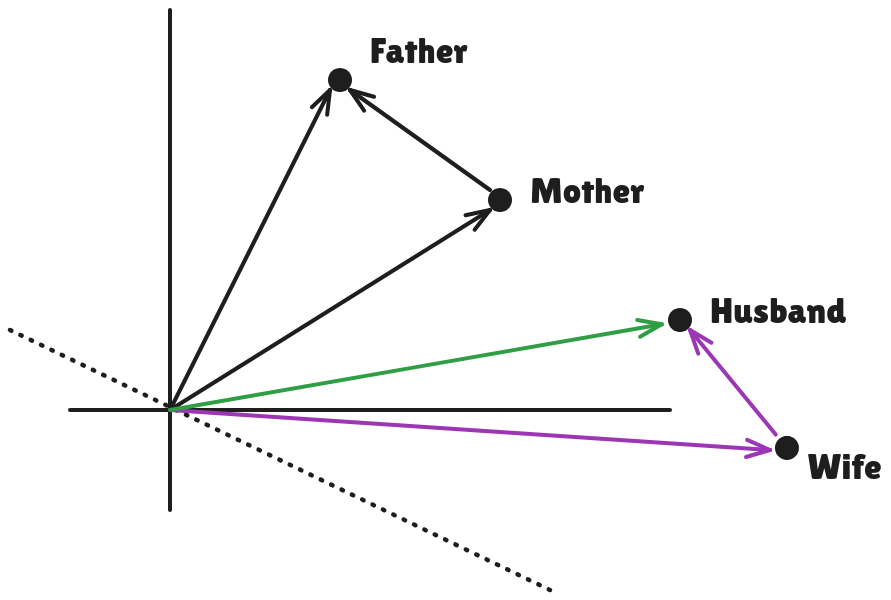
and we can see it uses some vector mathematics to compute the word "Husband".
Step-3 (Positional Encoding)
So, we've fired the RNNs because they were slow and forgetful, and brought in our shiny new transformer that processes words in parallel like a true multitasker.
But wait — if the transformer is reading all words at once, how does it know the order of the words?
Imagine you get this message:
"ate the dog the homework."
No amount of attention is going to help if you don't know who did what to whom, and when.
Enter: Positional Encoding
It's like giving each word a unique GPS coordinate in the sentence so the model knows: "Hey, 'ate' came after 'dog', not before."
Now, instead of just slapping an index number like "word #1", "word #2", etc., the transformer uses sine and cosine waves to encode position.
Yeah. Really.
Each position in a sentence is mapped to a unique combo of sine/cosine values. Why? Because it lets the model interpolate and extrapolate positions it hasn't seen before. It's like giving it a musical rhythm for the words.
Each word gets a slightly different "wave" signature based on its position.
Think of it as giving each token its own flavor — like unique spice blends in a recipe. The model learns not just what ingredient it is, but when to add it.
Step-4 (Multi-head Attention)
Alright, folks.
Time to talk about the magic sauce that makes GPT models borderline psychic.
You've heard the phrase:
"Pay attention!"
Well, transformers took that very personally.
Imagine you're reading a sentence:
"When the professor, who had a tendency to mumble, entered the room..."
By the time you get to "entered the room," your brain somehow knows the main subject was the professor, not the tendency.
That mental linking across long distances?
That's attention.
In transformers, attention is how the model decides which other words are important for understanding a given word.
So when GPT sees the word "entered," it goes, "Hmm... who's doing the entering here?"
And then it pays attention to "the professor."
Let's take a small sentence:
"The cake is delicious."
When processing the word "delicious," the model thinks:
"What is delicious?" 🤔
Looks at all the words in the sentence
"Ah! 'Cake' is delicious. Let me focus more on that!"
This mechanism is called self-attention — every word looks at every other word, including itself, and assigns scores to figure out how much to "attend" to each one.
Attention uses three vectors per word:
- Q = Query
- K = Key
- V = Value
Let's decode that:
Imagine a word sends out a Query:
"Hey, I'm trying to figure out who's important to me."
Every other word responds with a Key:
"Here's what I'm about."
Then, based on how well the Query matches the Key, the model grabs the Value.
It's like Tinder for words. Query swipes on Keys, and if there's a match, Value gets attention.
This is how the model builds a weighted understanding of which words matter most — mathematically.
Instead of doing attention once, transformers do it multiple times in parallel, each time with different Q, K, V matrices.
Think of it as several detectives reading the same sentence — one looking for verbs, one for nouns, one for relationships, etc.
Then they all combine their findings for a rich, multi-faceted understanding which is aka multi-head attention.
I'm deliberately leaving out the explanation of masked multi-head attention — and I challenge you to dig in and figure it out!
Hint: I've already dropped some clues about masking earlier in this blog. Go on a little treasure hunt and see if you can connect the dots!
Step-5 (Feedforward Layers)
Alright, you've just gotten this beautiful soup of attended information thanks to self-attention.
Now what?
We pass it through a brainy blender — the feedforward neural network — to do some serious number crunching.
The "Deep" in Deep Learning
Transformers don't just stop at attention. They also apply a fully connected neural network — separately and identically to each word/token's embedding.
Yes, each token gets its own private little MLP spa treatment.
Think of attention as gathering information, and feedforward layers as processing and transforming that info.
Step-6 (Output & Prediction — The Word Chooser)
All that number-crunching and self-attending and feedforwarding has brought us to this moment: What word comes next?
Final Vector → Vocabulary
At the end of all those transformer layers, every token has a final embedding — a big juicy vector full of meaning.
Now GPT has to turn that vector into a word.
How?
Enter the Output Layer: Linear + Softmax
The final step is a linear layer followed by a softmax, which works like this:
logits = final_vector × W_vocab + b_vocab probs = softmax(logits)
W_vocabis a big matrix mapping vector space → vocabulary space (e.g. 768 → 50,000+ words/tokens)softmaxsquashes the logits into probabilities that sum to 1
So now, GPT has a big list that says:
- "the": 0.12
- "cake": 0.001
- "banana": 0.07
- "quantum": 0.000001
- etc.
Choosing the Next Word
Once we've got this probability distribution, GPT can do one of several things:
- Greedy decoding: Pick the highest-probability word
- Sampling: Randomly choose based on probabilities (adds variety!)
- Top-k / Top-p sampling: More controlled randomness — avoid weird rare words
And boom — the next word is chosen.
Think of it as GPT saying, "I've deeply considered everything, and based on all this, the most likely next word is... 'delicious'."
Repeat Until You're Done
Once GPT picks a word, it adds it to the input, shifts everything right, and runs the whole model again to predict the next word.
It keeps doing this one word at a time until:
- It hits a stop token (
<end>), or - It reaches a max length (like 2048 or 8192 tokens)
This is how GPT generates an entire paragraph — word by word, predicting each based on the ones before it.
Conclusion
So, I hope I've kept my promise — that you either learned something new or gained a fresh perspective on something you already knew. What we've covered here barely scratches the surface (maybe not even 5%) of what GPT is capable of, but it's enough to show that it's not magic or wizardry. At its core, it's a beautiful blend of (not-so-simple) math, computer science, and — of course — a whole lot of GPU power.
It's easy to treat GPT like a black box, but behind the scenes is the tireless work of researchers, mathematicians, and engineers who've poured years of effort into making these models possible. Real people. Real work. Real breakthroughs.
And hey, if you've made it this far — kudos to you! In a world of 10-second attention spans and endless cat memes, sticking with a technical blog like this deserves a solid pat on the back.
That's all from me for now — thanks for reading, and I'll catch you in the next one!
References
- https://arxiv.org/abs/1706.03762 (Attention is all you need, white paper by Google)